
Nas últimas semanas, tenho demasiadamente visto comparações entre Kafka, RabbitMQ e SQS e também diversas provas de conceito utilizando o Kafka (somente) como message broker mas, você sabia que por definição o Kafka não é uma plataforma de mensageria? Pois é, pasme! Entrando no site do Kafka, não é esta a definição que você vai encontrar.

Segundo a Apache o Kafka é uma ferramenta de event streaming. Mas se você não sabe como streams se diferenciam de simples mensagens, esta definição não serve para muita coisa.
Message Queueing
Quando estamos trabalhando com Event Driven Design (EDA), os microserviços podem se comunicar de forma assíncrona disparando eventos em forma de mensagens. Um evento é algo que já aconteceu, passado, normalmente uma notificação, por exemplo: Utilizando o padrão publisher/subscriber o microserviço de Estoque se inscreveu na fila do microserviço de Pedidos e, então quando um pedido é concluído o microserviço de Pedidos dispara um evento (mensagem) chamado OrderCreatedEvent, contendo no body da mensagem OrderId e ProductId, para que o microserviço de Estoque possa abater o produto comprado do estoque. Perceba, que o payload de um evento como este é minuscúlo, não a toa o message size padrão do Simple Queue Service (SQS) é de 256 Kilobytes.
Event Streaming
Event Streaming, significa trabalhar com o dado em si ao invés das notificações referenciando o dado; Continuando o exemplo acima, imagine um cenário onde você precisa extrair todos os pedidos dos últimos três anos da tabela de Orders e inseri-los no ElasticSearch para coletar métricas e aprimorar as vendas. Como você vai transitar um payload de 5GB?
Vamos um pouco mais longe. Comumente escutamos o termo streamer, normalmente referindo-se as pessoas que fazem lives jogando; Definitivamente, este pode ser um ótimo exemplo para se entender como streams funcionam. Na prática, streaming ou live significa "ao vivo", cada novo frame nada mais é do que um chunk (pedaço de dado), que é transmitido (streamed) em real time para cada dispositivo (subscribed consumer), que por sua vez recebe esse binário e converte em frames novamente.
Simplificando, se você precisa monitorar dados em arquivos ou banco de dados para então enviar esses dados para outros arquivos ou outros banco de dados, você não precisa fazer essa integração na mão, você pode utilizar plataformas de event streaming, para te ajudar com esta tarefa. Aqui estão alguns exemplos, de possíveis integrações via streaming, para te ajudar assimilar a ideia de streams e streaming:
-
Enviar registros de uma tabela de um banco de dados SQL qualquer (MySQL, Oracle, SQL Server, Postgres, entre outros) para uma tabela em outro banco de dados SQL qualquer. Detalhe, não estamos falando de um job que roda uma única vez. Nas configurações de streaming, podemos deixar uma task (worker) escutando ativamente novos registros em tabelas e então replicando-os em bancos de dados/tabelas de destino. E o melhor, o banco de origem e o banco de destino não precisam ser iguais.
-
Enviar registros de um banco de dados SQL para um banco de dados NoSQL. Sim, isto é possível, você pode inclusive fazer transformações nos dados antes de inseri-los, tudo isto é nativamente suportado no Kafka.
-
Enviar registros de um arquivo de log para o ElasticSearch para coleta de métricas.
Incrível né? E esses são apenas alguns exemplos e você aí achando que o Kafka é só message broker. Agora que você é um discípulo de Kafka, espalhe a palavra para os amiguinhos.
Apesar de muito útil, esses são apenas exemplos simples, hoje em dia já existe inclusive integração com Cloud Providers, o que nos permite fazer coisas mais sofisticadas como coletar dados do S3, Dynamo, CloudWatch, Kinesis ou SQS e enviar para processamento em uma Lambda. Vou deixar aqui a lista completa dos conectores suportados.
Kafka Connect
Todos os exemplos acima são possíveis, desde que existam conectores (e existem). Os conectores, são plugins que instalamos em nosso Cluster Kafka Connect, com o objetivo de consumir dados de uma origem (Source) e então transformar (ou não) e inserir esses dados em um destino (Sink).
O Kafka Connect é uma solução que faz parte do ecosistema Kafka e nos permite fazer essas integrações de forma simplificada. Preparei uma implementação para demonstrar como isso funciona na prática.
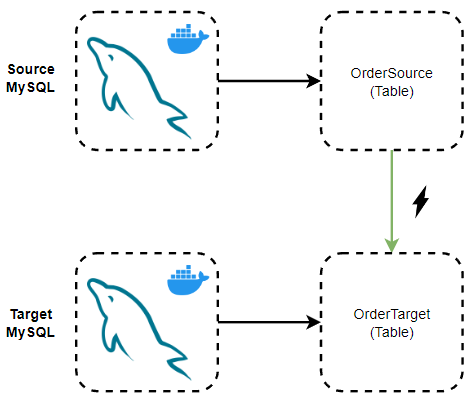
Neste exemplo, vamos realizar o stream de registros de uma tabela de origem chamada OrderSource em um banco de dados MySQL para outro banco de dados MySQL em uma tabela destino chamada OrderTarget; Ambos bancos de dados, rodando em conteineres, simulando dois servers distintos. A ideia é que, para cada novo registro inserido na tabela de origem, o mesmo deve ser replicado na tabela de destino. Esse é o docker-compose que vamos utilizar para criar a infraestrutura necessária.
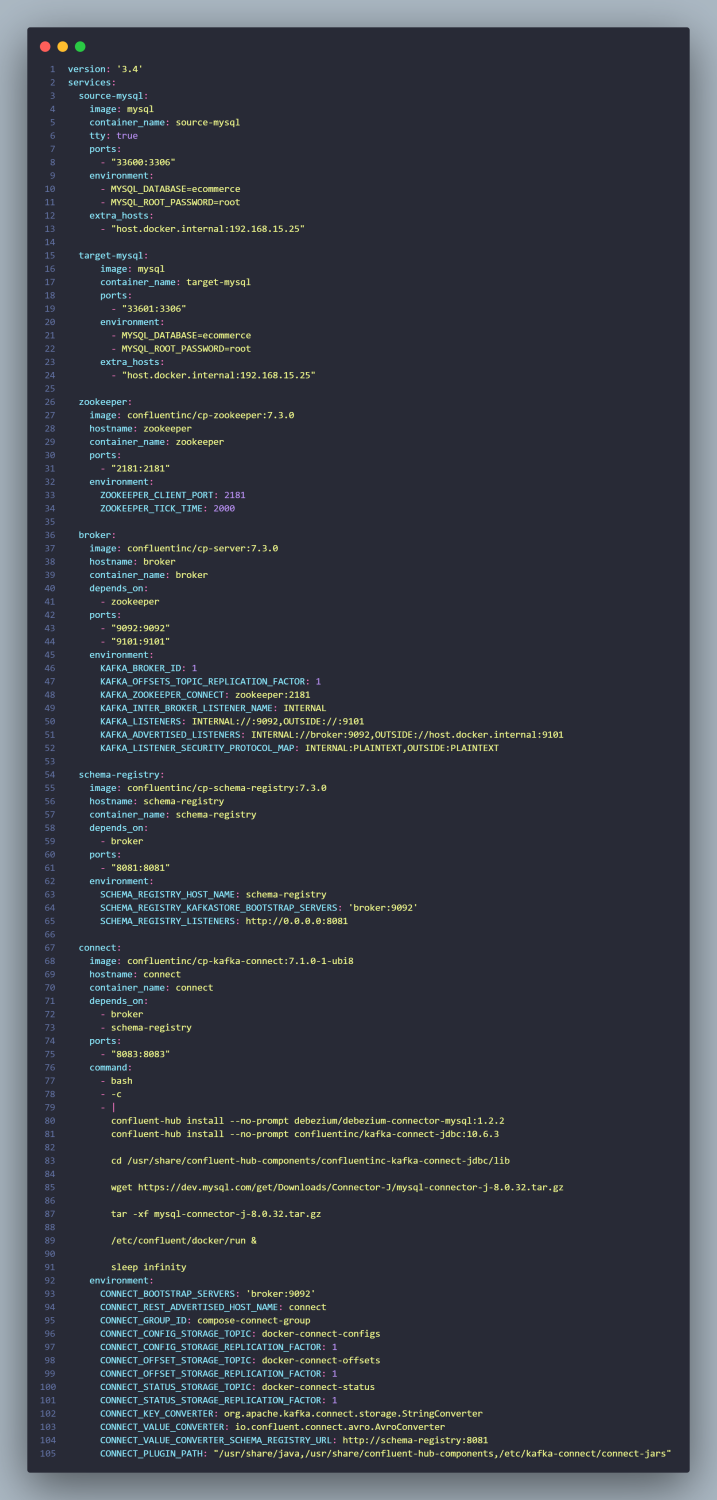
Estamos criando seis conteineres:
source-mysql: Neste container ficará hospedado o banco de dados MySQL de origem, contendo uma tabela chamada OrderSource, que terá os seus registros replicados para o banco de dados/tabela destino.
zookeeper: Este container faz parte da infraestrutura necessária para subir o Kafka e consequentemente o Kafka Connect. O Zookeeper é uma solução da Apache, que vai armazenar metadados dos offsets das mensagens lidas pelos consumers nas particões, metadados dos brokers e também dos tópicos, são dados de controle para garantir a orquestração dos serviços do Kafka. Exemplo: Se um broker/server (Kafka) do Cluster parar de responder, o Zookeeper é quem garante o failover. Se um consumer ficar indisponível durante a leitura da mensagem de um tópico, o Zookeeper é quem tem o indíce onde aquele Consumer parou e deve retomar o consumo das mensagens daquele tópico naquela partição.
broker: Este container é o servidor Kafka em si. É aqui que produtores e consumidores se conectarão para trocar mensagens em um tópico.
schema-registry: Este container é o schema-registry server que nada mais é do que um contrato, uma especificação de formato de mensagem que o Consumer deve esperar que o Producer emita.
connect: Este container é o Kafka Connect server, é aqui onde faremos as configurações de integrações utilizando streams via conectores.
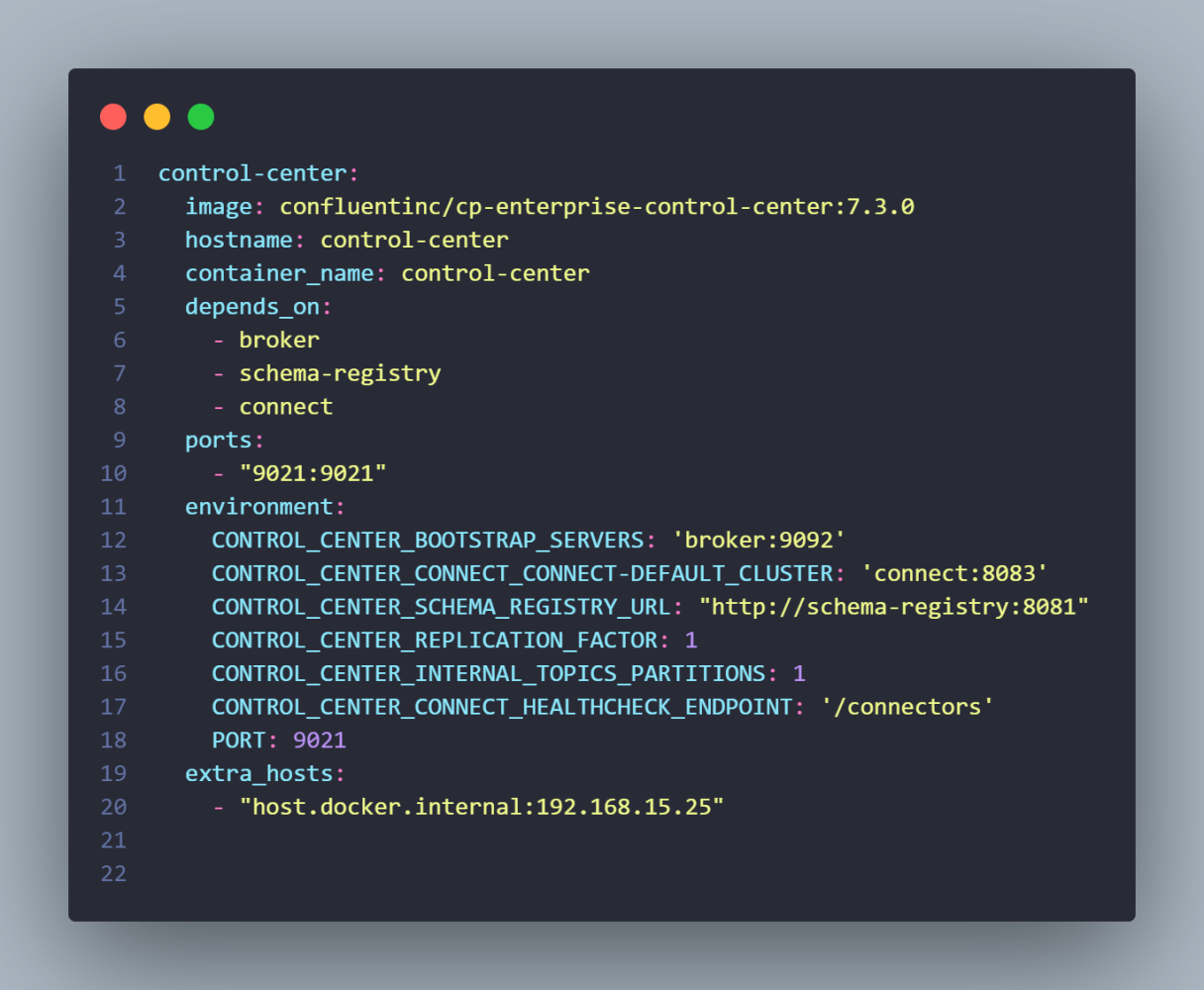
Opcionalmente, estou adicionando mais um container, o control-center. Por motivos didáticos, vou demonstrar as configurações de conectores via interface gráfica no control-center mas, todas poderiam ser normalmente feitas utilizando apenas linha de comando.
Hands On
A primeira coisa a se fazer é subir toda essa infraestrutura e então realizar a criação de alguns registros de teste em nosso banco de dados de origem:
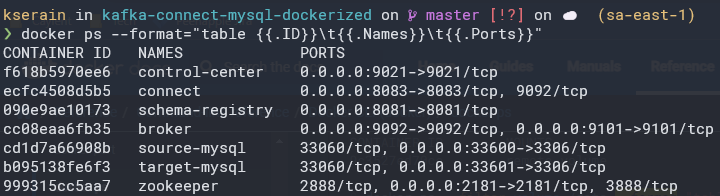
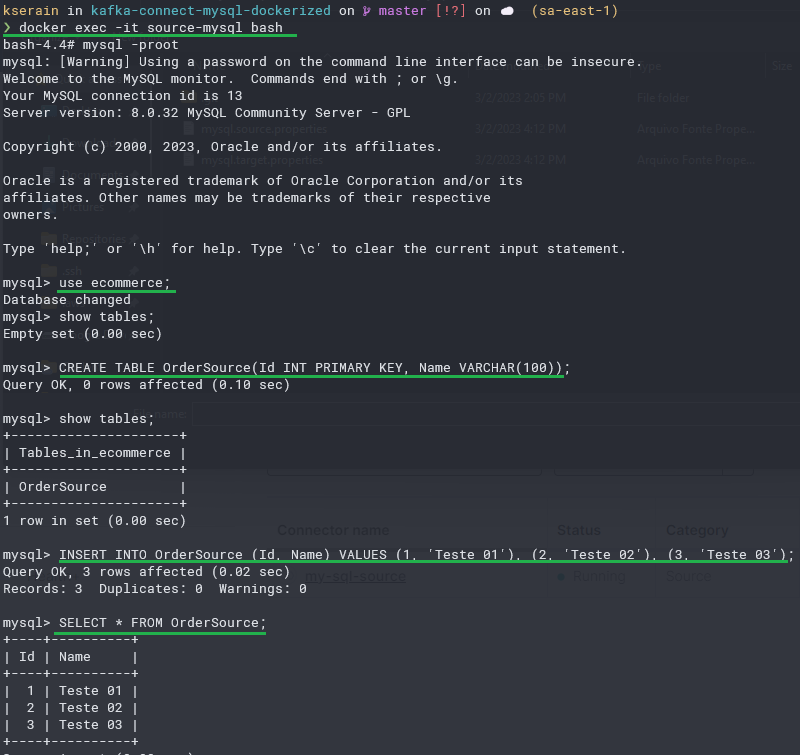
Com os registros devidamente configurados em nosso banco de dados de origem, podemos acessar o control-center, para configurar nossos conectores, só precisamos verificar em que porta o control-center está rodando.
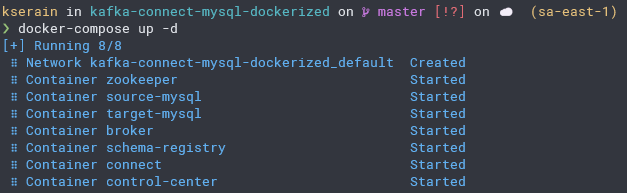
Porta 9021, excelente, vamos acessá-lo via browser.
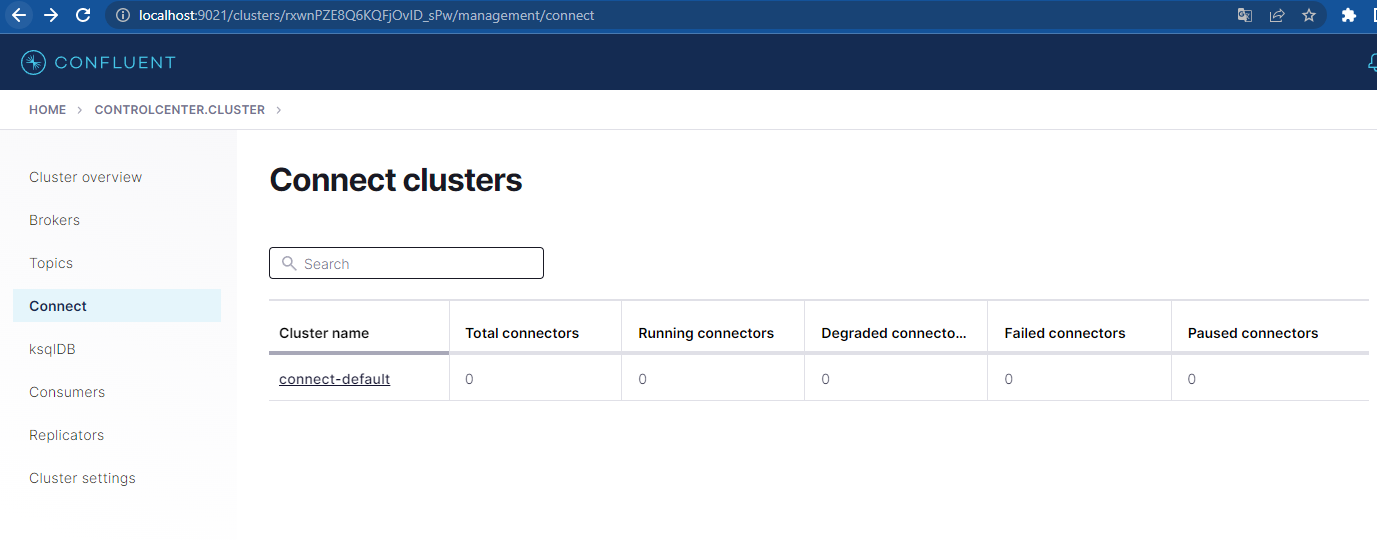
O control-center já identificou o Cluster Kafka Connect (connect-default), precisamos apenas adicionar os conectores. Selecione o cluster > Clique em adicionar conector > Adicione o arquivo abaixo.
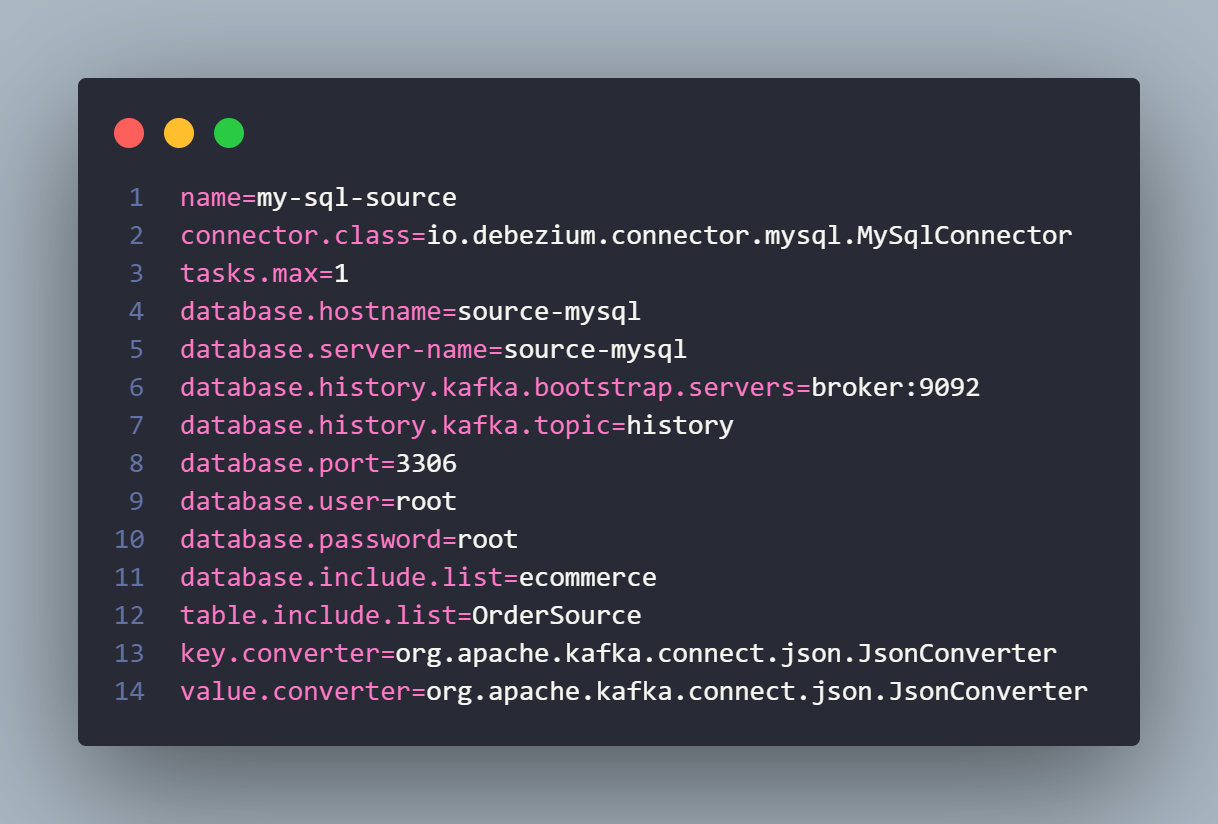
As configurações de conectores são feitas via properties. Acima está a configuração do conector de origem, de onde faremos streaming dos nossos dados. A especificação é basicamente servidor MySQL (container), usuário e senha, banco de dados e tabela.
Veja que diferentemente de quando adicionamos um conector do tipo Source, o conector do tipo Sink, solicita a especificação de um tópico para monitoramento.
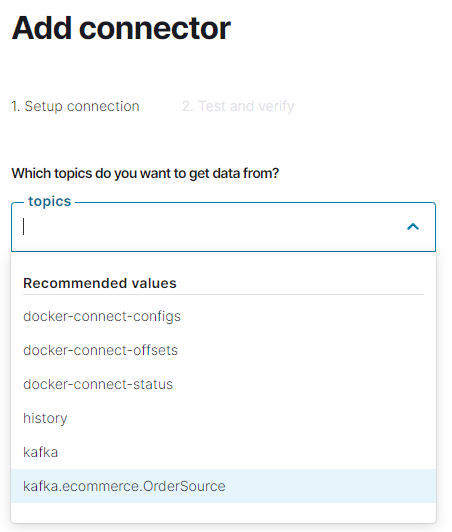
Selecione o tópico kafka.ecommerce.OrderSource e continue, se tudo deu certo, os dois conectores já devem estar rodando.
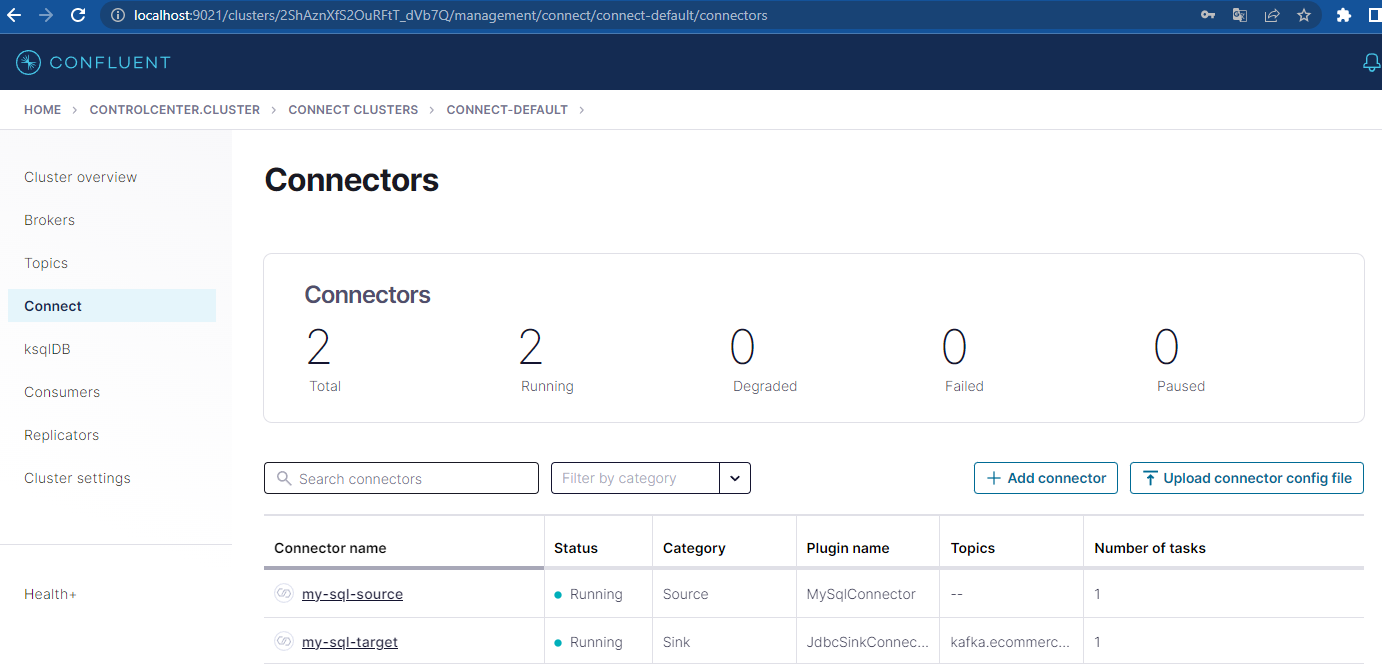
Só por curiosidade, vamos verificar nosso banco de dados destino.
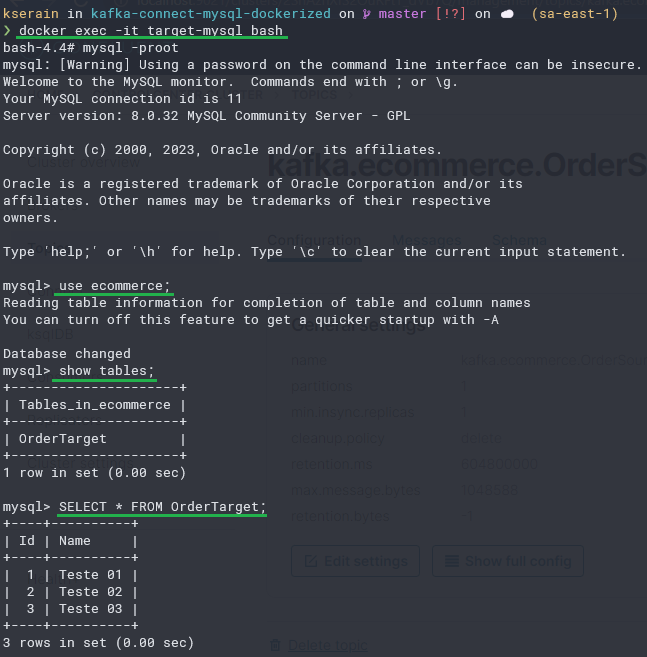
E Voilá! A tabela OrderTarget já foi automaticamente criada! E os dados inseridos na tabela de origem já foram automaticamente replicados! Loucura né? Como isso aconteceu? Assim:
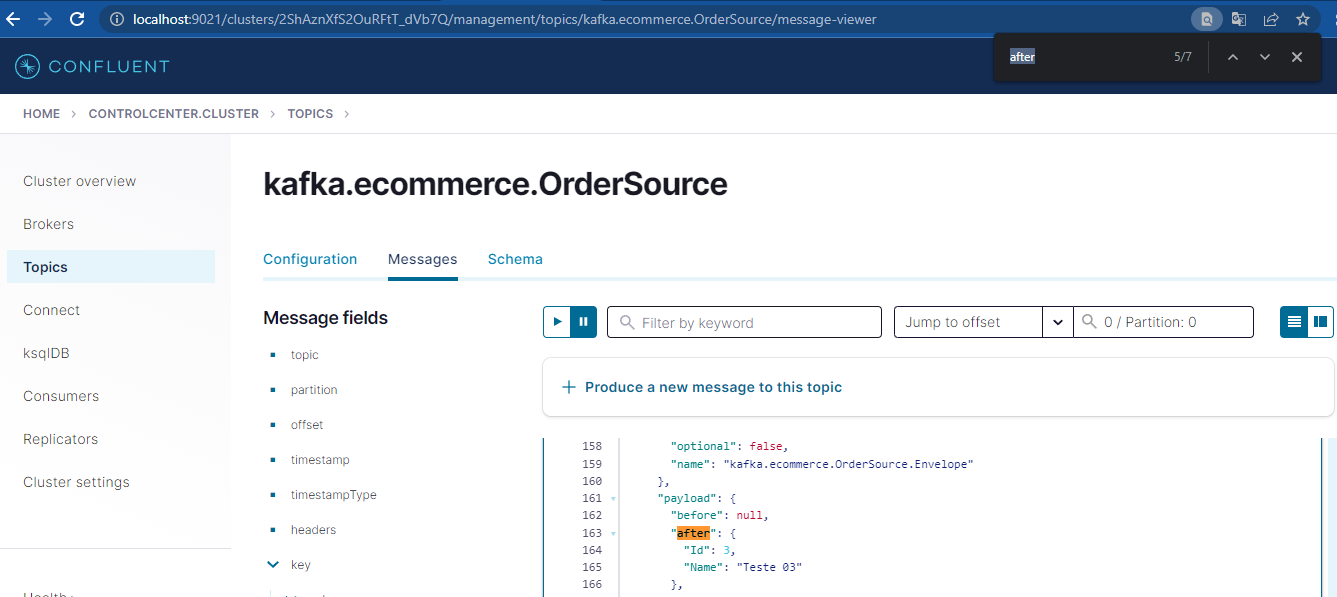
Mais acima falamos do campo after na mensagem do tópico, veja que o payload (colunas e valores da tabela) estão armazenados nele. Essa é uma das três mensagens que chegaram no tópico.
Conclusão
Espero que você tenha entendido que por definição Kafka não é um message broker mas sim uma plataforma de Event Streaming. Se você chegou até aqui, meus parabéns, você é guerreiro; Sei que este não foi um artigo tão leve de digerir, pois o conteúdo é denso mas, a questão é que entender streaming pode fazer uma chave virar na sua cabeça da próxima vez que você ouvir a palavra integração.
